


DeepSeek 基本信息

DeepSeek是一家中国人工智能初创公司开发的大型语言模型和AI助手。该公司由杭州深度求索人工智能基础技术研究有限公司和北京深度求索人工智能基础技术研究有限公司及其关联公司共同开发。DeepSeek的核心产品是基于深度神经网络算法的DeepSeek Chat大语言模型,该模型经过大规模自监督学习的预训练和针对性的优化训练。
DeepSeek能够执行广泛的基于文本生成的任务,包括回答问题、生成内容、编写代码等。用户可以通过chat.deepseek.com访问DeepSeek Chat界面,只需一个有效的电子邮件地址即可注册使用。DeepSeek的用户界面类似于ChatGPT,左侧显示交互历史,底部有文本提示框用于输入问题。
DeepSeek的主要功能包括文本生成、对话能力、代码编写、数学计算和推理任务等。它可以集成到各种下游系统或应用中,为用户提供智能对话和内容生成服务。DeepSeek还提供API接口,允许开发者将其集成到自己的应用中。
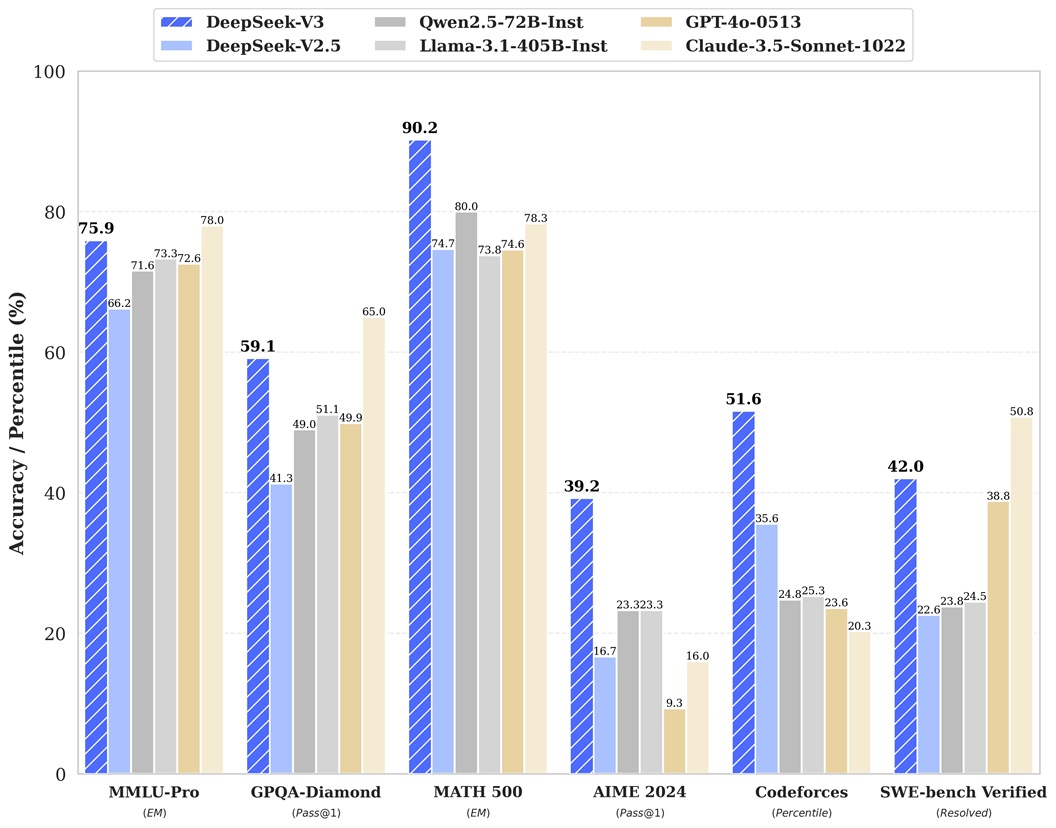
DeepSeek引起关注的一个主要原因是其在各项基准测试中的出色表现。据报道,DeepSeek在数学、编码和推理任务等多个基准测试中取得了与OpenAI的GPT模型相当的结果,在某些领域甚至超越了GPT。特别是在编码任务中,DeepSeek声称达到了97%的成功率,这一成绩相当令人印象深刻。
DeepSeek-V2.5版本在主要的大模型排行榜上表现出色。在AlignBench测试中,它排名前三,超过了GPT-4并接近GPT-4-Turbo的水平。在MT-Bench测试中,DeepSeek与LLaMA3-70B不相上下,并优于Mixtral 8x22B。这些成绩表明DeepSeek在整体性能上已经达到了顶级水平。
DeepSeek的另一个优势是其在特定领域的专长。它在数学、代码和推理方面表现尤为出色。这种专业化使DeepSeek在某些应用场景中可能比其他通用模型更具优势。此外,DeepSeek的开源模型支持128K的上下文长度,这为处理长文本和复杂任务提供了更大的灵活性。
与ChatGPT和Google Gemini相比,DeepSeek在某些方面展现出独特的优势。例如,在回答时间上,DeepSeek与ChatGPT相当,有时甚至比Google Gemini更快。这种快速响应能力对于需要实时交互的应用来说是一个重要优势。
DeepSeek 主要功能
- 自然语言处理:DeepSeek能够理解和生成自然语言,可以进行语言翻译、文本摘要、情感分析和命名实体识别等任务
- 问答系统:DeepSeek可以回答用户提出的各种问题,包括常识问题、专业问题、历史问题和科技问题等
- 智能对话:能与用户进行智能对话,理解用户的意图和情感,并给出相应的回答
- 代码生成:DeepSeek具备强大的代码生成能力,可以帮助开发者快速生成代码片段,提高开发效率
- 多语言编程支持:在多语言编程测评中表现优异,超越多个竞争对手
- 信息推荐:根据用户的历史行为和偏好,推荐相关的内容和信息
- 内容写作:根据用户提供的关键词和主题,自动生成相关的文章和内容
- 智能客服:可以代替人工客服,回答用户的咨询和问题,提高客服效率和质量
- 联网搜索:类似于GPT search的功能,可以根据网络搜索到的内容提供答案
- 深度思考:在回答问题之前,会进行多步骤的推理和思考,类似于OpenAI的功能
- API和Web服务:提供API和Web服务,方便用户在不同场景下集成和使用DeepSeek的功能
DeepSeek 技术创新
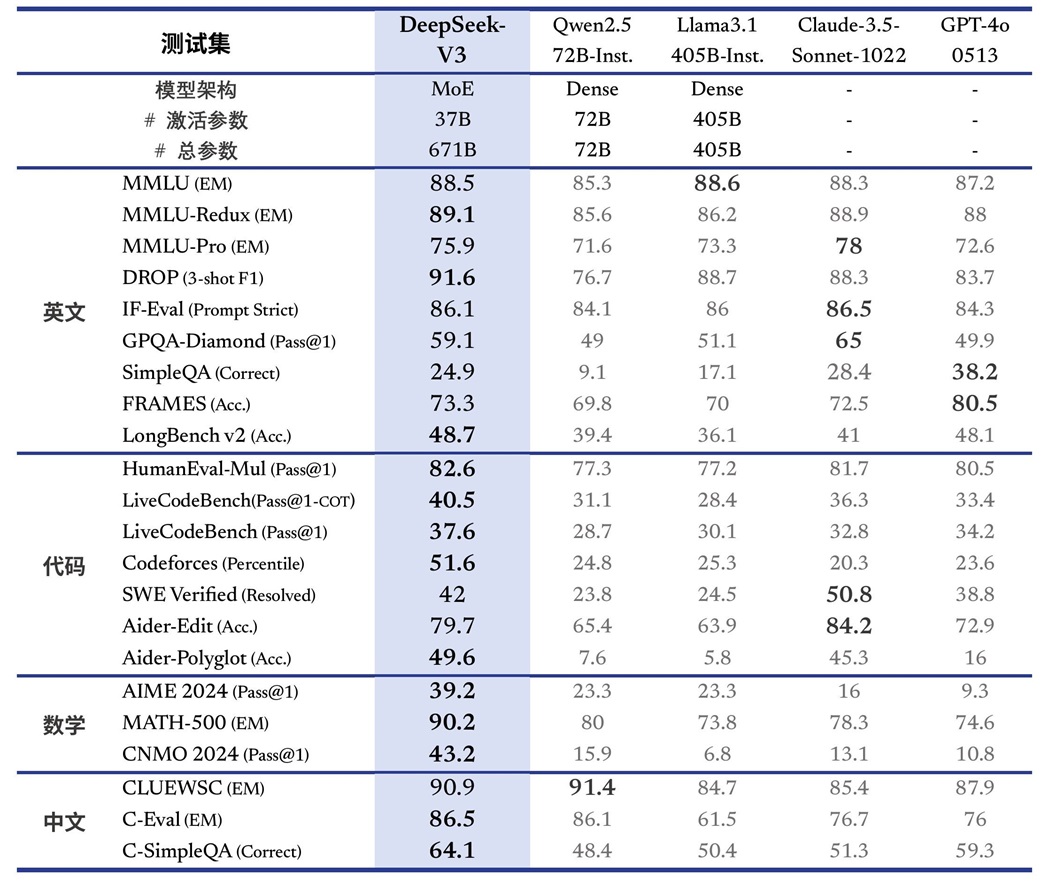
- 混合专家(MoE)架构:DeepSeek-V3拥有6710亿参数,但每次输入仅激活370亿参数,大幅降低计算成本同时保持高性能。
- 多头潜在注意力(MLA):这种架构实现了高效的训练和推理。
- 无辅助损失的负载平衡策略:最小化负载平衡对模型性能的负面影响。
- 多tokens预测训练目标:提升了模型的整体性能。
- 高效训练框架:采用HAI-LLM框架,支持16-way Pipeline Parallelism、64-way Expert Parallelism和ZeRO-1 Data Parallelism,降低训练成本。
- 多token预测(MTP)技术:允许模型同时预测多个连续位置的token,提高训练效率并更好捕捉token间依赖关系。
- 多阶段训练方式:包括基础模型训练、强化学习(RL)训练和微调,使模型在不同阶段吸收不同知识和能力。
- "顿悟时刻":通过RL框架,AI自发形成类人推理能力,超越预设规则限制。
这些技术创新使DeepSeek在性能、效率和成本方面都取得了显著优势,在多项基准测试中超越了其他主流模型,甚至在某些领域接近或超过GPT-4和Claude-3.5-Sonnet等顶级闭源模型。
DeepSeek 发布历史
2023年11月2日,DeepSeek发布了其首款模型DeepSeek Coder,该模型免费向研究人员和商业用户开放。该模型的代码以MIT许可协议开源,同时附加了关于“开放和负责任的下游使用”的许可协议。
2023年11月29日,DeepSeek推出了DeepSeek LLM,参数规模达到67B,旨在与当时其他大型语言模型竞争,其性能接近GPT-4。然而,该模型在计算效率和可扩展性方面面临挑战。同时还发布了该模型的聊天版本DeepSeek Chat。
2024年5月,DeepSeek-V2发布。据《金融时报》报道,其价格低于同类产品,每百万输出标记仅需2人民币。滑铁卢大学Tiger Lab的排行榜将DeepSeek-V2列为LLM排名的第七位。
2024年11月,DeepSeek R1-Lite-Preview发布,专为逻辑推理、数学运算和实时问题解决任务设计。DeepSeek声称其在美国数学邀请赛(AIME)和MATH等基准测试中的表现超过了OpenAI o1。然而,《华尔街日报》表示,在用2024年AIME的15道题测试时,o1模型比DeepSeek R1-Lite-Preview更快得出解答。
2024年12月,DeepSeek-V3发布。该模型拥有6710亿参数,训练耗时约55天,成本为558万美元,显著低于同类模型。它基于14.8万亿标记的数据集进行训练。基准测试显示,其性能超越了Llama 3.1和Qwen 2.5,并与GPT-4o和Claude 3.5 Sonnet相匹敌。该模型采用专家混合技术和多头潜在注意力Transformer架构,包含256个路由专家和1个共享专家,每个标记激活超过370亿参数。
DeepSeek.com
DeepSeek.com
2025年1月20日,DeepSeek-R1和DeepSeek-R1-Zero发布。这两款模型基于V3-Base,与V3一样,均采用专家混合架构,总参数量为6710亿,每次激活参数量为370亿。同时还发布了一些“DeepSeek-R1-Distill”模型,这些模型并非基于R1,而是类似于LLaMA和Qwen等开源权重模型,基于R1生成的合成数据进行微调。R1-Zero完全通过强化学习(RL)训练,没有任何监督微调(SFT)。它采用群组相对策略优化(GRPO),通过群组分数而非评价模型估算基线。其奖励系统基于规则,主要包括两类奖励:准确性奖励和格式奖励。R1-Zero的输出可读性较差,且会在输出中切换使用中英文,因此对R1进行了训练以解决这些问题并进一步提高推理能力。
DeepSeek 应用场景
- 自然语言处理:DeepSeek可以进行语言翻译、文本摘要、情感分析和命名实体识别等任务
- 智能对话:能与用户进行智能对话,理解用户的意图和情感,并给出相应的回答
- 代码生成和辅助:DeepSeek-Coder-V2支持338种编程语言,可以生成代码、解释代码含义、修复代码错误等
- 问答系统:回答用户提出的各种问题,包括常识、专业、历史和科技等领域
- 内容创作:根据用户提供的关键词和主题,自动生成相关的文章和内容
- 智能客服:代替人工客服,回答用户的咨询和问题,提高客服效率和质量
- 多模态交互:处理图像、音频等多种数据形式,适用于智能助手和移动应用等场景
- 数学和推理任务:在数学计算和复杂推理任务方面表现出色
- 信息推荐:根据用户的历史行为和偏好,推荐相关的内容和信息
- 量化投资:作为幻方人工智能公司的产品,DeepSeek在量化投资领域也有应用
这些应用场景涵盖了从日常生活到专业领域的多个方面,展示了DeepSeek作为大型语言模型的多功能性和广泛适用性。
DeepSeek 低成本原因
DeepSeek成本低的主要原因有以下几点:
- 创新的模型架构:DeepSeek采用了混合专家模型(MoE)架构,包括路由专家和共享专家,通过稀疏激活机制大幅减少了计算量。
- 低精度训练:DeepSeek V3原生使用FP8混合精度训练,显著降低了计算和存储需求。
- 多头潜在注意力(MLA)机制:这种改进的注意力机制通过低秩键值联合压缩和解耦旋转位置嵌入,提高了计算效率。
- 优化的训练流程:DeepSeek团队在训练稳定性、多词同时预测等方面进行了深入优化,进一步降低了训练成本。
- 算法创新:DeepSeek证明了算法有很大的提升空间,不需要依赖大量GPU和算力来堆砌效果。
这些创新使得DeepSeek能够以约600万美元的成本训练出一个600B参数的大模型,被认为是工程上的奇迹。据报道,DeepSeek用10-15分之一的成本就训练出了比肩OpenAI GPT-4水平的模型,并且完全开源。这种低成本高效能的模式可能会对整个AI行业产生深远影响,包括刺激更多专用推理模型的诞生和改变企业对API的依赖。
DeepSeek 主要竞争对手
- OpenAI:DeepSeek的R1模型在多项基准测试中与OpenAI的o1模型展开直接竞争,在某些领域甚至超越了o1。
- Google:DeepSeek的搜索功能被认为与Google的Gemini Deep Research不相上下。
- Meta(Facebook):DeepSeek的模型在性能上超越了Meta的Llama 3.1。
- Anthropic:DeepSeek在多个领域的准确性上超越了Anthropic的Claude Sonnet 3.5。
- Perplexity AI:DeepSeek的搜索功能被认为已经超越了Perplexity。
- 国内竞争对手:包括字节跳动、百度、阿里、腾讯和智谱AI等,这些公司在DeepSeek引发的价格战中也参与其中。
DeepSeek的突破性进展引起了这些竞争对手的高度关注,尤其是在性能和成本效率方面。例如,Meta的工程师们正在紧急分析DeepSeek的技术,而Perplexity AI的CEO也表示将把DeepSeek R1的推理能力引入他们的产品中。这种竞争态势显示了DeepSeek在全球AI领域已经成为一个不容忽视的重要参与者。
DeepSeek上市了吗?如何投资?
DeepSeek是一家成立于2023年的中国人工智能初创公司,专注于开发大型语言模型。作为一家新兴的AI公司,DeepSeek目前仍处于快速发展阶段,主要通过发布创新的AI模型和技术来吸引业界关注。公司目前还没有IPO上市,还无法通过公开市场参与DeepSeek投资。


1F
感觉这篇文章是ai写的
B1
@ 666 哈~
B2
@ 美股百科 DeepSeek 目前属于智障阶段,简单的问题比人回答快,出个稍微有难度的就扯淡了,卡壳了。我出了道题:我有8万元,是应该先还车贷呢,还是先还房贷,房贷还有12年,剩下24万元,利率是 4.9%还款方式是等额本金,8万提前还后,还款年限更改为5年;车贷8万,1年期限,不过要支付3%违约金,利率也是 4.9%,还款方式是等额本息,请用数据替我生成方案进行比较优势。尼玛 ,屁都不放一个,卡壳了,如果人类用着智障去代替人类的话,一定是自取灭亡。记好了 ,这玩意是人类开发出来的,不是这玩意开发了人类,懂不,大傻叉!
B3
@ 你大爷 帮你问了,不知对错,答案如下:
以下是针对您的情况进行的数据分析和建议方案:
一、关键数据整理
项目 房贷 车贷
剩余本金 24万元 8万元
剩余期限 12年(144个月) 1年(12个月)
利率 4.9%(等额本金) 4.9%(等额本息)
提前还款金额 8万元(缩短至5年) 8万元(需支付3%违约金)
利息计算规则 利息逐月递减 利息分摊更均匀
二、两种方案详细对比
方案1:提前还房贷(剩余本金从24万→16万,期限缩短至5年)
节省利息
原剩余利息(12年等额本金):约 7.1万元
新剩余利息(5年等额本金):约 2.0万元
净节省利息:7.1万 – 2.0万 = 5.1万元
月供变化
原月供:首月约2646元(递减) → 新月供:首月约3320元(递减)。
总还款压力短期增加,但长期利息大幅减少。
方案2:提前还车贷(支付3%违约金)
成本分析
违约金:8万 × 3% = 2400元
原剩余利息(1年等额本息):约 2149元
净损失:2400元 – 2149元 = -251元(多花251元)。
实际效果
提前还款反而需多支付251元,得不偿失。
三、综合建议
优先选择:提前还房贷
核心优势
节省5.1万元利息,远高于车贷方案的亏损。
房贷利率虽与车贷相同,但房贷期限长、本金高,利息累积效应显著。
风险提示
房贷缩短年限后,月供压力可能短期上升(首月增至3320元),需确保现金流稳定。
补充策略(若现金流充裕)
部分还款车贷:若车贷允许部分提前还款且违约金比例更低,可考虑少量还款(如还4万),减少利息损失。
投资替代方案:若您有收益率高于4.9%的稳健投资(如国债、大额存单),可保留资金增值,而非提前还款。
B1
@ 666 就是的
B1
@ 666 666
来自外部的引用